Hermes for E-Business Suite
Graphite Connect Standard E-Business Suite Integration Connector
Summary
Hermes is a lightweight software application that clients deploy on a server inside their private network, safeguarded by their firewall. Its primary function is to regularly query the Graphite Public API for updates related to suppliers and then synchronize these updates with Oracle EBS using the provided stored procedures.
The software is designed to only initiate outbound HTTPS connections to the Graphite Public API and does not host any open ports or handle incoming requests from external sources.
For support and monitoring purposes, Hermes sends back error notifications and selected integration activity details to Graphite.
Architecture
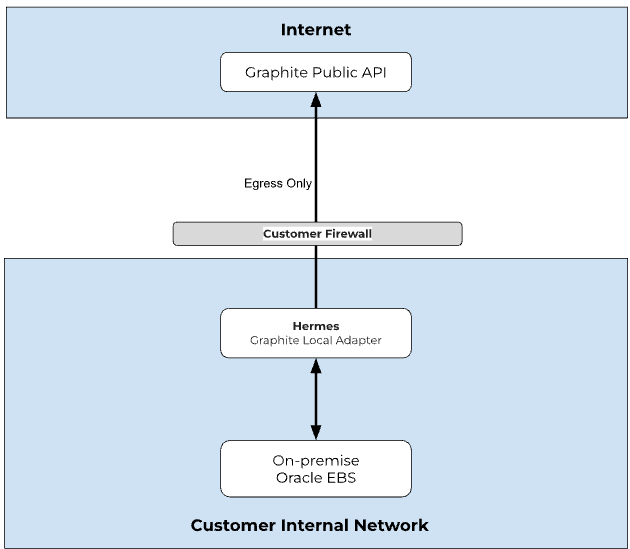
Requirements
For PL/SQL Package:
- Oracle Database Version >= 11g 12.2.4 or greater.
- An EBS user who has access to manager vendors and banking data across the required operating units.
For Hermes Binary:
- You can obtain the latest Hermes installation for:
- The testing build of Hermes can be downloaded here (These builds are often unstable and only for testing new features/bug fixes):
- If compiling from source: Go Version >= 1.21
- Outgoing and Incoming connection to
*.projectgraphite.comandapp.graphiteconnect.com - Hermes Configuration File
Configuration File
The configuration file allow Hermes to create the communication from Graphite to the Oracle Database. Please see the bundled encryption utility for information on storing this file securely.
- Location: Same directory as the Hermes binary
- File Name:
config.json - Additional Notes: When copying the configuration, remove all comments (
//). Including these will prevent Hermes from parsing the JSON properly.
Example for EBS
{
"adapters": [
{
"dsn": "oracle://tiger:SCOTT@localhost:1521/ebs_ebsdb", // connection string for oralce database
"adapterType": "ebs", // type of the adapter. Will always be ebs
"adapterConfig": {
"userId": 123, // user ID. Used in apps_initialize
"applicationId": 123, // application ID. Used in apps_initialize
"responsibilityId": 123, // responsibility ID. Used in apps_initialize
"packageName": "graphite_sync", // name of the package. If not in APPS schema, pass with <schema_name>.<package_name>
"withPljson": true,
"packageLogLevel": "debug" // what level of debugging to use for the package. trace, debug, warn, error, panic are available values
},
"graphitePublicApi": {
"url": "https://api-poc.projectgraphite.com", // URL of the environment. This will be provided
"interfaceName": "interfaceName", // Name of the external interface. This will be provided
"apiKey": "US000000.000000000.000000000000000000000" // Graphite API Key. Instructions will be provided.
},
"logging": {
"level": "debug", // Log Level: trace, debug, warn, error
"outputPath": "path/to/log/file.log", // Where to store the log file. This is a relative path to the binary
"jsonLogging": true // log in JSON or flat text. JSON avoids some compatibility issues.
}
}
]
}
Multiple Concurrent Adapters
To run multiple concurrent adapters, include another object with the fields provided in the above example into the array. If you already have an executing process, restart it to include the additional adapter. This can make and maintain multiple database connections, allowing for multiple environments/multiple databases to be run on the same Hermes process.
Encryption
The Hermes configuration file gives the adapter the necessary credentials and context to connect and make updates to the database. Due to the sensitivity of this data, the configuration is always encrypted with AES-256 encryption on the file system. At runtime, Hermes will decrypt in memory without ever re-writing the decrypted configuration file on the file system.
Hermes will store the required decrypted data in memory to maintain connection with the database.
To enable this, Hermes come bundled with an encryption utility to facilitate easy encryption and decryption with several supported encryption key providers.
- Location: Same directory as the Hermes binary
- File Name:
encryption_config.json - Additional Notes: When copying the configuration, remove all comments (
//). Including these will prevent Hermes from parsing the JSON properly.
Configuration
Hermes uses an encryption configuration to specify what encryption method should be used and any additional parameters that need to be provided.
Encryption Key Providers
Password
To encrypt using a password, set the fetchType to password. Once prompted, enter the password to encrypt/decrypt the configuration file.
Environment Variable
To encrypt using en environment variable, set the fetchType to environmentVariable and provide the environment variable the key is stored in with the environmentVariable key.
Named Pipes / Sockets
To encrypt using named pipes (Windows)/sockets (Unix and Unix-like), set the fetchMethod to named_pipes. This will create a listener waiting for the password from a key provider. Launch another hermes process with the argument --provide. Once provided, the initial process will begin executing.
Secret Managers
Hermes supports storing the encryption key in a cloud provider secret manager. To use, set the fetchMethod to one of the secret providers specified below. Find your secret manager below for setup instructions:
-
AWS Secret Manager
- fetchMethod:
aws_secretmanager - To use AWS Secret Manager, the shared credential file must be stored in
~/.aws/credentialsor on running on a machine with proper IAM permissions.
- fetchMethod:
Examples
All Configuration Options
{
"fetchMethod": "password", // Method for fetching key. Values are environmentVariable, password, named_pipes, aws_secretmanager
"alwaysFetch": false, // --encrypt and --decrypt by default will use the "password" fetch method. set to true to always use the provided fetch method
// environmentVariable
"environmentVariable": "ENV_NAME", // The name of the environment variable to fetch the key from
// aws_secretmanager
"awsRegion": "us-east-1", // The AWS region to fetch the key from
"awsSecretKey": "SECRET_KEY" // The AWS secret key to fetch the key from
}
AWS Secret Manager
{
"fetchMethod": "aws_secretmanager",
"alwaysFetch": true,
"awsRegion": "us-east-1",
"awsSecretKey": "superSecretKey"
}How to Encrypt
Once the configuration file is created and located in the same directory as the Hermes binary, execute the command: ./hermes –encrypt. By default, Hermes will use the password fetch method to encrypt the file. Set alwaysFetch to true to override this behavior and use the fetchMethod instead.
Once the key is provided, Hermes will encrypt the configuration file with the provided key.
After the file is encrypted, the original configuration file will be overwritten and renamed it to config.json.encrypted.
How to Decrypt
If a config.json.encrypted file exists in the same directory of the Hermes binary, execute the ./hermes -decrypt method to decrypt back to plain text. By default, Hermes will use the password fetch method to encrypt the file. Set alwaysFetch to true to override this behavior and use the fetchMethod instead.
Hermes will prompt with an incorrect key if the file did not decrypt to valid JSON. This will not overwrite the encrypted file with the incorrect key.
This key will be used to decrypt the contents of the configuration file.
Integration Data Flow
The Graphite Sync project is an Oracle PL/SQL integration designed to synchronize supplier data from a JSON-based payload into the Oracle E-Business Suite (EBS) environment. It handles the creation and updating of suppliers, supplier sites, contacts, and bank account information.
The main entry point is the graphite_sync.syncronize procedure, which parses an input CLOB containing JSON and orchestrates calls to various sub-packages (graphite_sync_supplier, graphite_sync_site, etc.) to process the data.
Core Process Flow & Conditional Logic
The integration's logic is built around a "create or update" pattern, checking for the existence of records before deciding which Oracle API to call.
Main Execution Flow (graphite_sync.syncronize)
graphite_sync.syncronize)-
Initialization: The
syncronizeprocedure initializes the EBS environment usingfnd_global.apps_initialize. -
JSON Extraction: The input
in_clobis parsed into apljsonobject. Theextract_json_elementsfunction then separates the payload into its main components:supplier,sites(array),post_site_batch,connection_metadata, and anignore_missingflag. -
Supplier Sync:
graphite_sync_supplier.process_supplier_from_jsonis called.- It first runs the
is_updatecheck to see if aVENDOR_IDexists and is valid. - It calls either
ap_vendor_pub_pkg.create_vendororap_vendor_pub_pkg.update_vendor_public. - If an
organizationobject exists in the supplier JSON, it also callshz_party_v2pub.update_organizationto update TCA-level details. - This step provides the key
supplier_output(containingvendor_idandparty_id) needed for all subsequent operations.
- It first runs the
-
Site Sync (Loop): The code then iterates through the
elements.site_arrarray. For each site object in the array, thesync_siteprocedure is called. This procedure executes the following sub-flow:- a. Process Site:
graphite_sync_site.process_site_from_jsonis called. This performs the "create vs. update" logic for the supplier site itself (usingap_vendor_pub_pkg.create_vendor_siteorupdate_vendor_site_public). It also updates associated TCA records (hz_location_v2pub.update_locationandhz_party_site_v2pub.update_party_site) ifaddressorparty_siteobjects are present in the JSON. This step provides thesite_output(vendor_site_id,party_site_id,location_id). - b. Bank Sync (Sub-loop): The code checks if the
ignore_missingflag isfalseand if abanksarray exists on the current site object.- If
true, it loops through each bank object in thebanksarray. - For each bank, it calls
sync_site_bank, which is a wrapper forgraphite_sync_bank.process_bank_objects_from_json. This single procedure handles the "create vs. update" logic for all four bank entities (Bank, Branch, Bank Account, and Intermediary Account) and also manages the critical logic for linking the bank account to the supplier site usingiby_disbursement_setup_pub.set_payee_instr_assignment.
- If
- c. Contact Sync (Sub-loop): The code checks if the
ignore_missingflag isfalseand if acontactsarray exists on the current site object.- If
true, it loops through each contact object. - For each contact, it calls
sync_site_contact, which is a wrapper forgraphite_sync_contact.process_contact_from_json. This procedure finds or creates the contact and links it to the supplier and site usingap_vendor_pub_pkg.create_vendor_contactorupdate_vendor_contact_public.
- If
- d. Second Pass Site Update:
process_site_from_jsonalso checks for asite_second_pass_keyobject. If present, it re-runsap_vendor_pub_pkg.update_vendor_site_publicto apply updates that must happen after the initial create (e.g., setting a default pay site ID).
- a. Process Site:
-
Post-Site Batch Update: After the main site loop (step 4) is complete, the code checks if
elements.post_site_batch(a separate JSON object) exists.- If
true, it callsgraphite_sync_site.process_post_site_batch. This procedure iterates through all sites processed in the current run and applies a common set of updates to them. This is used for updates that can only be performed after all sites exist.
- If
-
Error Handling: The entire
syncronizeprocedure is wrapped in an exception block. If any Oracle API call fails, theraise_if_error_statushelper procedure raises a customapi_error_statusexception (-20002). The main exception block catches this, formats the error (including the call stack fromfnd_msg_pub), and writes it into anerrorsarray in theack_jsonportion of theout_clob.
Key Conditional Logic: "Create vs. Update"
The system uses a consistent pattern to determine whether to call a create_ or update_ API.
- Supplier (
graphite_sync_supplier.is_update): Checks if theVENDOR_IDkey exists in the supplier JSON and if thatVENDOR_IDcorresponds to a valid record in theap_supplierstable. - Site (
graphite_sync_site.is_update): Checks if theVENDOR_SITE_IDkey exists in the site JSON and if that ID exists inap_supplier_sites_allfor the given vendor_id. - Contact (
graphite_sync_contact.is_update): First,set_existing_contact_idsattempts to find a contact using thevendor_id,vendor_site_id, andemail_address. Theis_updatefunction then simply checks ifcontact_rec.vendor_contact_idwas populated by this check. - Bank Entities (
graphite_sync_bank): This package uses a slightly different pattern. It first calls aset_existing_..._idprocedure (e.g.,set_existing_bank_id,set_existing_branch_id) which uses aniby_..._check_..._existAPI. The corresponding..._is_updatefunction then checks if the ID record (e.g.,bank_rec.bank_id) is no longer null.
Special Bank Logic
The graphite_sync_bank package has unique conditional logic for linking bank accounts:
- Joint Owner: When updating a bank account (
process_bank_acct_from_json), the code callsbank_acct_needs_joint_owner. This checks if the supplier'sparty_idis already an owner of the account. If not, it callsiby_ext_bankacct_pub.add_joint_account_ownerto link them. - Site Assignment: After a bank account is processed,
bank_acct_needs_to_be_linkedis called. This checks if the bank account is already assigned to the specific supplier site. If not, it callsprocess_assign_bank_to_site, which usesiby_disbursement_setup_pub.set_payee_instr_assignmentto create the link, making the bank account usable for payments for that site.
JSON Parsing (graphite_sync_json_parser)
graphite_sync_json_parser)Parsing is not done using native JSON functions directly. Instead, a custom object type apps.graphite_sync_json_parser is used as a wrapper. This provides two major benefits: type safety and specialized null handling.
- Initialization: A parser is initialized with a
pljsonobject:parser := graphite_sync_json_parser(json_data => some_pljson_object);. - Data Access: It provides simple member functions for data extraction:
get_string(k varchar2, nullable boolean default false)get_number(k varchar2, nullable boolean default false)get_date(k varchar2, nullable boolean default false)get_object(k varchar2)get_array(k varchar2)get_bool(k varchar2)
- Error Handling: If a key is not found or is of the wrong type (e.g.,
get_stringis called on a JSON number), the parser callsgraphite_sync_json_utils.raise_wrong_typeto throw a detailed, custom exception (-20001) that stops execution. - Type Coercion: The
get_numberfunction can safely convert both JSON numbers and JSON strings (e.g., "123") into an Oraclenumber. - Date Format: The
get_datefunction expects dates to be inMM-DD-YYYYformat.
Critical Null Handling Logic
A key feature of the parser is its handling of nulls, which is essential for Oracle EBS update APIs.
In Oracle APIs, passing a NULL value to an update procedure typically means "no change to this field." To explicitly set a field to NULL, a special constant (e.g., fnd_api.g_null_char) must be passed.
The parser handles this automatically:
- The
parseris initialized with anis_updateflag. - When calling
get_string,get_number, orget_date, a second parameternullablecan be set totrue. - Logic: If
is_updateistrue, andnullableistrue, and the JSON key is missing or its value isnull, the parser returns the correspondingfnd_api.g_null_...constant (g_null_char,g_null_num,g_null_date) instead of a standardNULL.
This ensures that when a JSON payload omits a nullable field during an update, the integration correctly nulls out the value in Oracle EBS.
Called Oracle E-Business Suite Public APIs
The project relies exclusively on Oracle's public APIs to ensure data integrity and compatibility.
Foundation & Utilities
fnd_global.apps_initialize: Sets the user, responsibility, and application context required by all EBS APIs.fnd_msg_pub.get: Used in theraise_if_error_statusprocedure to retrieve detailed error messages from the Oracle error stack after an API call fails.
Supplier & Site Management (ap_vendor_pub_pkg)
ap_vendor_pub_pkg)create_vendor: Creates a new supplier record (inap_suppliers) and its underlying TCA party record (inhz_parties).update_vendor_public: Updates an existing supplier record.create_vendor_site: Creates a new supplier site (inap_supplier_sites_all) and its associated address records (inhz_locations,hz_party_sites).update_vendor_site_public: Updates an existing supplier site.create_vendor_contact: Creates a new supplier contact (inap_supplier_contacts) and the underlying TCA relationship records.update_vendor_contact_public: Updates an existing supplier contact.
TCA Management (HZ - Trading Community Architecture)
hz_party_v2pub.update_organization: Called after a supplier is created/updated to sync additional organization-level details (like DUNS number,jgzz_fiscal_code, etc.) to thehz_partiesandhz_organization_profilestables.hz_location_v2pub.update_location: Called after a site update to sync detailed address attributes (likeaddress_lines_phonetic,timezone_id, etc.) to thehz_locationstable.hz_party_site_v2pub.update_party_site: Called after a site update to sync party-site-level details (likemailstop,party_site_name, etc.) to thehz_party_sitestable.
Bank & Payment Management (IBY - Payments)
iby_ext_bankacct_pub.check_bank_exist: Checks for a bank's existence based on country, name, and bank number.iby_ext_bankacct_pub.create_ext_bank: Creates a new bank in the TCA structure.iby_ext_bankacct_pub.update_ext_bank: Updates an existing bank.iby_ext_bankacct_pub.check_ext_bank_branch_exist: Checks for a bank branch's existence under a specific bank.iby_ext_bankacct_pub.create_ext_bank_branch: Creates a new bank branch.iby_ext_bankacct_pub.update_ext_bank_branch: Updates an existing bank branch.iby_ext_bankacct_pub.check_ext_acct_exist: Checks for an external bank account's existence based on bank, branch, account number, and currency.iby_ext_bankacct_pub.create_ext_bank_acct: Creates a new external bank account record iniby_ext_bank_accounts.iby_ext_bankacct_pub.update_ext_bank_acct: Updates an existing external bank account.iby_ext_bankacct_pub.add_joint_account_owner: Adds a party (the supplier's party) as an owner to an existing bank account. This is used if the bank account already exists but is owned by a different party.iby_ext_bankacct_pub.create_intermediary_acct: Creates an intermediary bank account record.iby_ext_bankacct_pub.update_intermediary_acct: Updates an intermediary bank account record.iby_disbursement_setup_pub.set_payee_instr_assignment: This critical API links the external bank account (as a payment instrument) to the supplier site (as the payee), making it available for payments.
Tables Selected from:
- ap_suppliers
- ap_supplier_sites_all
- ap_supplier_contacts
- hz_locations
- hz_party_sites
- hz_parties
- hz_relationships
- hz_org_contacts
- hz_contact_points
- hz_code_assignments
- iby_ext_bank_accounts
- iby_intermediary_accts
- iby_account_owners
Updated 4 months ago